Guide d'utilisation de TaxRef-Match
Avant-propos
a). Nous vous recommandons l'utilisation de Mozilla Firefox (télécharger).
b). Vous pouvez télécharger ici un fichier d'exemple.
c). Veuillez vous reporter au paragraphe 6) pour plus de détails sur les différents types de réconciliation.
1). Importer le fichier de données
Veuillez choisir un fichier à traiter (.csv ou .txt). Reportez-vous au paragraphe 5) pour plus de détails sur les fichiers .csv.
Ce fichier doit respecter les conditions suivantes :
- L'encodage des caractères du fichier doit être au format standard (ANSI/Windows-1252) ou au format UTF-8 sans BOM.
- La première ligne doit contenir le nom des colonnes dans cet ordre : nom_complet;classification;fk
- Vos données doivent suivre l'ordre indiqué par la première ligne et être séparées par des points-virgules (";").
- nom_complet (obligatoire) : nom le plus complet possible, y compris autorité
- classification : tous les noms de taxons supérieurs dont vous disposez, en latin et séparés par des virgules
- fk (obligatoire) : votre id/clé unique personnelle
- Le fichier doit contenir moins de 10000 lignes de données.
- Il ne doit pas y avoir de doublons dans les noms d'espèces.
Exemple :
nom_complet;classification;fk
helix lapicidus linné 1758);mollusca,gastropoda,helicidae;12
Cyclops minutus O.F. Müller, 1776;;30
Canis lupus altaicus (Noack, 1911);;1
2). Si votre fichier comporte plus de 10 lignes de données
Le traitement peut être long. Les résultats vous seront envoyés par e-mail. Il contiendra un lien qui vous permettra de télécharger un fichier contenant les résultats.
Vous êtes alors invités à préciser les options suivantes :
- Le format de fichier contenant les résultats : CSV ou XML.
- Le format d'encodage des caractères : Standard (ANSI / Windows-1252) ou UTF-8. Le format UTF-8 propose une palette plus large de caractères, mais requière une manipulation spéciale avec Microsoft Excel notamment. Référez-vous au paragraphe 4). Ouvrir un fichier CSV au format UTF-8 avec Microsoft Excel, LibreOffice, OpenOffice pour avoir plus de détails sur l'ouverture d'un fichier CSV en UTF-8.
- Votre adresse e-mail : l'adresse à laquelle vous recevrez le lien pointant vers le fichier contenant les résultats.
3). Si votre fichier comporte moins de 10 lignes de données
Vous serez redirigés vers une page proposant un tableau avec les résultats. Voici le contenu de ce tableau :
- Nom cité : Le nom que vous avez spécifié dans votre fichier de données.
- Classification : La classification que vous avez spécifiée dans votre fichier de données.
- Id (FK) : L'identifiant (clé unique personnelle) que vous avez spécifié dans votre fichier de données.
- CD_NOM : Code du taxon dans l'INPN.
- Nom complet : Nom complet dans l'INPN.
- Similarité : Taux de réconciliation trouvé. Plus cette valeur est proche de 1, plus la réconciliation est a priori proche de votre requête.
- Niveau taxonomique le plus précis : Niveau taxonomique le plus précis déduit par l'algorithme de réconciliation.
- Type de réconciliation : Type de réconciliation utilisé par l'algorithme.
- Sélection : Si l'algorithme a trouvé plusieurs résultats pour votre requête, vous êtes invités à choisir le résultat qui vous convient le mieux.
Choisissez le format de fichier et le format d'encodage des caractères (cf. paragraphe précédent), puis cliquez sur Enregistrer pour exporter le résultat dans un fichier.
4). Ouvrir un fichier CSV au format UTF-8 avec Microsoft Excel, LibreOffice, OpenOffice
Pour ouvrir un fichier CSV avec Microsoft Excel au format UTF-8, vous devez suivre les étapes suivantes :
- Lancez Microsoft Excel ;
- Allez dans l'onglet Données ;
- Cliquez sur A partir du texte ;
- Choisissez votre fichier ;
- Au niveau de la liste Origine du fichier, choisissez 65001 : Unicode (UTF-8) ;
- Choisissez l'option Délimité, puis cliquez sur Suivant afin de choisir le séparateur (Point-virgule) ;
- Cliquez à nouveau sur Suivant, puis sur Terminer.
Les suites LibreOffice et Apache OpenOffice proposent de choisir le format d'encodage des caractères à l'ouverture du fichier.
5). Créer un fichier .csv
Qu’est-ce qu’un fichier .csv ?
Lorsque vous travaillez sur votre logiciel de tableur (Microsoft Excel, LibreOffice Calc, OpenOffice Calc, …) chaque colonne est séparée par des traits verticaux comme sur un tableau classique. TaxRef-Match ne lisant pas les fichiers de ces tableurs, il va être nécessaire de passer par un autre type de fichier : le .csv.
Un fichier .csv est un fichier texte où chacune de vos colonnes de votre tableau ne sera plus séparée par des traits verticaux mais par des points-virgules.

Le tableau sous Excel de la figure 1 devient le fichier présenté dans la figure 2. Chaque ligne correspond à une ligne de votre tableur et chaque colonne est séparée par un point-virgule. Vous noterez qu’il n’y a plus aucune mise en forme (texte en gras et lignes du tableau dessinées).

Créer un fichier .csv
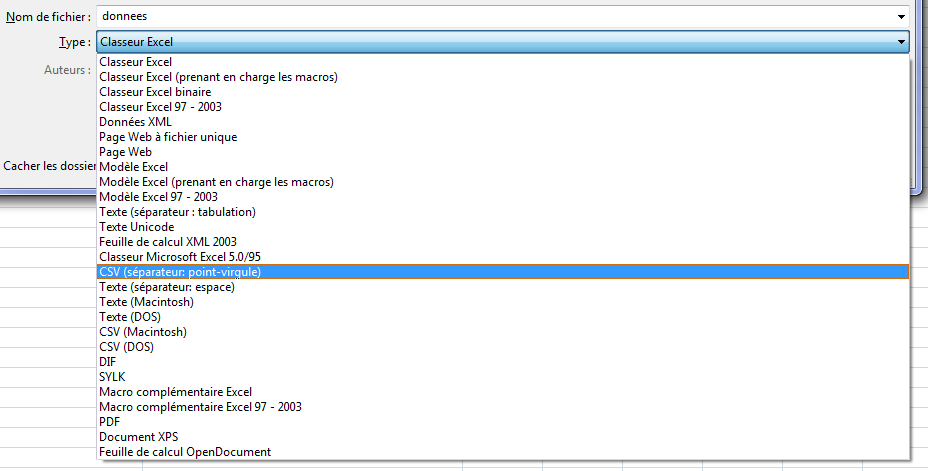
Un fichier .csv peut se créer directement depuis votre logiciel de tableur. Allez dans « Enregistrez-sous », saisissez le nom de votre choix (ne mettez pas d’accents ou de caractères spéciaux) puis sélectionnez CSV (séparateur point-virgule) dans la liste des choix de type de fichier (figure 3). Cliquez sur Enregistrer puis conserver le format du fichier. Votre fichier est maintenant créé.
6). Les différents types de réconciliation
| Type de réconciliation | Signification | Exemples |
|---|---|---|
| 1 - Nom complet normalisé | Nom scientifique complet avec autorité et date | Paracentrotus lividus (de Lamarck, 1816) |
| 2 - Nom complet normalisé sans date | Nom scientifique complet avec autorité | Paracentrotus lividus (de Lamarck) |
| 3 - Nom scientifique normalisé | Nom scientifique complet | Paracentrotus lividus |
| 4 - Phonétique Nom complet | Erreur d'écriture du nom ou de l'autorité | Entelerus aequorus (Linnaeus, 1758) (Nom contenu dans le fichier initial) a été relié à : Entelurus aequoreus (Linnaeus, 1758) (Nom de référence) |
| 5 - Phonétique Nom complet sans date | Erreur d'écriture du nom ou de l'autorité | Festuca giganthea (L.) Vill. (Nom contenu dans le fichier initial) a été relié à Festuca gigantea (L.) Vill., 1787 (Nom de référence) |
| 6 - Phonétique Nom scientifique | Erreur d'écriture du nom | Gammagobius steinitzi (Nom contenu dans le fichier initial) a été relié à Gammogobius steinitzi Bath, 1971 (Nom de référence) |
| 7 - Phonétique Genre / taxon terminal | Si le taxon est indiqué comme sous espèce dans le fichier en entrée alors qu'il est au rang d'espèce dans TAXREF, alors le lien est fait. | Nigella arvensis L. subsp. Arvensis (Nom contenu dans le fichier initial) a été relié à Nigella arvensis L., 1753 (Nom de référence) |
| 8 - Phonétique taxon terminal / auteur | Permet de trouver les taxons qui ne sont pas regroupés dans le même genre entre le fichier en entrée et TAXREF. | Mystacides nigra (Linné, 1758) (Nom contenu dans le fichier initial) a été relié à Nigrotipula nigra nigra (Linnaeus, 1758) (Nom de référence) |
| 9 - Phonétique par complétion | Utilise le début de la chaine de caractères pour retrouver des taxons | Securigera varia (fourni par Robert) (Nom contenu dans le fichier initial) a été relié à Securigera varia (L.) Lassen, 1989 (Nom de référence) |
Définition des termes :
Normalisation : l’algorithme remplace les majuscules en minuscules, remplace les caractères accentués par des caractères non accentués pour les noms et les noms d’auteur. Pour les noms d’espèces le sous genre est supprimé. Pour les auteurs, les abbréviations sont identifiées et remplacées par le nom complet : par exemple L. pour Linnaeus.
Exemple : PARAcentroTus (sous-genre) Lividus LAMARCK 1816 sera normalisé en paracentrotus lividus lamarck 1816.
Phonétisation : il s’agit d’une normalisation améliorée où des lettres sont remplacées par d’autres. Cela permet d’identifier les erreurs d’écriture.